In my last post, we talked about homology and Betti numbers. We had a very simple example with a simplicial complex $K$ and we were able to easily compute $H_1(K)$ and $\beta_1(K)$. But that wasn’t really the whole story.
To write an algorithm that can find the Betti numbers of any given (finite) simplicial complex, we actually need to know more about how to read off the geometric information of the input complex and what to do with that information.
(Most of the material in this post can be found in Munkres, Elements of Algebraic Topology $\S 11$.)
Let’s first lay out the basics.
A(n abstract) simplicial complex is a collection $K$ of finite non-empty sets such that if $\sigma$ is an element of $K$, so is every non-empty subset of $\sigma$.
An element $\sigma$ of $K$ is called a simplex of $K$; its dimension is one less than the number of its elements. We may refer to $\sigma$ as a $p$-simplex or denote it as $\sigma^p$ to indicate its dimension $p$.
Each nonempty subset $\tau$ of $\sigma$ is called a face of $\sigma$; we say that $\tau$ is incident to $\sigma$ and denote it $\tau \prec \sigma$.
The dimension $d$ of $K$ is the largest dimension of one of its simplices. A $d$-simplex of $K^d$ is called a facet of $K$.
Given a finite complex $L$, we say that there is a labeling of the vertices of $L$, which means that there is a surjective function $f$ mapping the vertex set of $L$ to a set of labels (usually $\{0,1,2, \dots\}$ or $\{1,2, \dots\}$). Corresponding to this labeling is an abstract complex $K$ whose vertices are the labels and whose simplices consist of all sets of the form $\{f(v-0), f(v_1), \dots, f(v_n)\}$, where $v_0, \dots, v_n$ span a simplex of $L$.
This labeling mumbo-jumbo is essentially formalizing the obvious. We want to refer to specific simplices of $K$ and the convention used is to name it by its vertices.
One important property of a simplicial complex is that for every cell $\sigma$ in $K$, all of the faces of $\sigma$ are also in $K$. This property we will exploit when setting up our problem.
Step 1: Setting up the input
For a given simplicial complex $K^d$ of dimension $d$, we need only the set of $d$-simplices of $K$, the facets of $K$, as the input for our algorithm. With this list we can determine all the simplices of $K$ and their connectivity.
We’re now ready to set up all of our $C_p$’s, the $p$-chain groups of $K$. Actually, what we really have is the just the basis elements of the $C_p$, but that’s all we need. For each $p= 0, \dots, d$, the basis of $C_p$ is the set of $p$-simplices of $K$.
Let $F$ be our facet list of $K^d$. Every element of $F$ contains $(d+1)$ elements. For any $i=0, \dots, d$, the basis of $C_i$ will be the union of all subsets of elements of $F$ of length $i+1$.
So if $K$ is just two triangles, $F = \{ [1 \, 2\, 3],[2\, 3\, 4]\}$, then the basis of $C_1(K)$ is just the set of edges of $K$ or $\{[1\, 2], [1\, 3], [2\, 3], [2\, 4], [3\, 4]\}$, all length 2 subsets of elements of $F$. Even though edge $[2\, 3]$ is in both triangles, we only need to count it once.
Step 2: Setting up the boundary map
The boundary maps $\partial_p$ are the main characters in homology groups. From group theory, we know that all we really need to know about a homomorphism $f: G \to G’$ is how $f$ acts on the basis elements of $G$ in terms of the basis elements of $G’$.
More formally, let’s take a look at this definition:
Definition (matrix of a homomorphism) Let $G$ and $G’$ be free abelian groups with bases $a_1, \dots, a_n$ and $a_1′, \dots, a_m’$, respectively. If $f: G \to G’$ is a homomorphism, then $$f(a_j) = \sum_{i=1}^{m} \lambda_{ij}a_i’$$ for unique integers $\lambda_{ij}$. The matrix $(\lambda_{ij})$ is called the matrix of $f$ relative to the given bases for $G$ and $G’$.
The chain groups $C_p$ are the free abelian groups. And our boundary maps $\partial_p: C_p \to C_{p-1}$ are the homomorphisms between them. To learn more about the boundary maps, we must further analyze the matrix of $\partial_p$.
Step 3: Computing the Smith Normal Form
To understand what the boundary map is doing, let’s first recall a nice theorem from algebra.
Theorem (normal form) Let $G$ and $G’$ be free abelian groups of ranks $n$ and $m$, respectively; let $f: G \to G’$ be a homomorphism. Then there are bases for $G$ and $G’$ such that, relative to these bases, the matrix of $f$ has the form $$B=\left[\begin{array}{c|c}\begin{matrix}b_1 & ~ & 0 \\ ~ & \ddots & ~ \\ 0 & ~&b_q\end{matrix} & 0 \\ \hline 0 & 0\end{array}\right]$$ where $b_i \ge 1$ and $b_1 | b_2| \dots | b_q$.
This matrix is uniquely determined by $f$ and is called the normal form for the matrix of $f$.
To get from some jumbled up matrix $(\lambda_{ij})$ to its normal form, we perform what are called elementary row and column operations. These operations are
exchange row $i$ and row $k$
multiply row $i$ by $-1$
replace row $i$ by (row $i$) + $q$ (row $k$), where $q$ is an integer and $k \ne i$,
plus the 3 respective column operations.
Perhaps you remember seeing the elementary row operations from linear algebra. It’s important to note that here we’re only allowing integer multiplication for operation type 3 (and 6 for the column operations).
Step 4: What it means
Recall what our goal was: to compute the homology groups of some finite simplicial complex $K$. And we know that all homology groups $H_p \cong \mathbb{Z}_{t_1} \times \cdots \times \mathbb{Z}_{t_k} \times \mathbb{Z}^{\beta}$ can be written in terms of their Betti numbers $\beta$ and their torsion coefficients $t_1, \dots t_k$.
Now that we have the normal form for all the boundary maps $\partial_p$ for $p=0, \dots, d$, we can easily read off this information.
Torsion coefficients: The entries of the normal form for the matrix of $\partial_p: C_p \to C_{p-1}$ that are greater than 1 are the torsion coefficients of $K$ in dimension $p-1$.
Betti numbers: Let $B_i$ be the normal form for the matrix of $\partial_i: C_i \to C_{i-1}$. The Betti number of $K$ in dimension $p$ is $$\beta_p = \text{rank} C_p – \text{rank} B_p – \text{rank} B_{p+1}.$$
So we’re done.
Or we should be, but we’re not. If we’re done why, then, are people still working on developing homology algorithms?
I started writing a post about Homology Algorithms but realized that some discussion about homology should come first. And for those of you who already know what homology is, we should at least be on the same page in terms of language and notation. Besides, there’s more than one way to think about homology.
The way that I understand homology—the way I describe it here—is influenced almost entirely by Carsten Lange. He helped me understand the basics of algebraic topology so that I can read about discrete Morse theory without feeling like a total oaf. This also means that we are thinking about homology with the eventual goal of computing (i.e., with a computer) the homology of some explicit, finite discrete topological space. In particular, we will work with simplicial complexes.
And before I begin, let me just say: Big ups to Carsten and all dedicated educators like him who, for countless hours, over many days and weeks, sit together with students one-on-one until they have the confidence to seek knowledge on their own.
Homology in topology
The big question in topology is whether or not two spaces are homeomorphic. To say that two spaces are homeomorphic, we need only find any homeomorphism between them. But to say that two spaces are not homeomorphic, we would have to show that no function between them is a homeomorphism. One way to handle this latter (infinite) case is by using topological invariants.
A topological invariant is a property of a space that can be used to distinguish topological spaces. For example, say we have two sacks labeled $A$ and $B$. We can’t see inside them, but we can tell that sack $A$ has one item in it while sack $B$ has two. Clearly the contents of sack $A$ and sack $B$ cannot be the same.
However, if $A$ and $B$ both have one item each, we can’t tell whether those two items are of the same type. Perhaps one is a steak and the other a rice crispy treat—clearly very different objects, both nutritionally and topologically. (Can you tell I missed lunch?)
The topological invariant described in these examples is connectedness, which is only useful when the number of connected components is different. But if they have the same number of connected components, we can’t say definitively whether the objects are of the same topological type. And that’s how it works with all topological invariants.
Definition (topological invariant) Given two topological spaces $K_1$ and $K_2$, a map $\tau$ is a topological invariant if whenever $\tau(K_1) \neq \tau(K_2)$, then $K_1 \ncong K_2$. But if $\tau(K_1) = \tau(K_2)$, then $K_1 \overset{?}{\cong} K_2$ and we don’t know whether they are homeomorphic or not.
Homology groups are topological invariants. We take some geometric information about the topological space, form some algebraic object (specifically, a group) containing that information, then apply some machinery from group theory to say something about the original space.
And if two topological spaces give rise to homology groups that are not isomorphic, then those two spaces are not homeomorphic.
Definition of Homology
Let’s jump right in with a definition, then explain it in detail using an example.
Definition (homology group) For a topological space $K$, we associate a chain complex $\mathcal{C}(K)$ that encodes information about $K$. This $\mathcal{C}(K)$ is a sequence of free abelian groups $C_p$ connected by homomorphisms $\partial_p: C_p \to C_{p-1}$. \begin{align*}0 \overset{\partial_{d+1}}{\longrightarrow} C_d \overset{\partial_{d}}{\longrightarrow} C_{d-1} \overset{\partial_{d-1}}{\longrightarrow} \cdots \overset{\partial_{2}}{\longrightarrow} C_1 \overset{\partial_{1}}{\longrightarrow} C_0 \overset{\partial_{0}}{\longrightarrow} 0\end{align*} Then the $p$-th homology group is defined as \begin{align*}H_p(K):= \text{ker}(\partial_p) / \text{im}(\partial_{p+1}).\end{align*}
That’s a lot of terms we have yet to define.
Let’s start at the beginning with our input space $K$. We can assume that $K$ is a simplicial complex since we’ll only be dealing with simplicial complexes and they’re just nice to handle. So $K$ is a simplicial complex of dimension $d$. This means that for any face $\sigma \in K$, its dimension is at most $|\sigma| \le d$.
Figure 1: Simplicial complex $K$ with vertices labeled 1,2,3,4.
In Figure 1, we have our simplicial complex $K$. I’ve labeled the vertices so it’s easier for me to refer to the many parts of $K$. Our complex $K$ consists of
one 2-cell: $f_1 = [2 \, 3\, 4]$;
five 1-cells: $e_1=[1 \, 2], e_2=[1 \, 4], e_3=[2 \, 3], e_4=[2 \, 4], e_5=[3 \, 4]$; and
four 0-cells: $v_1=[1], v_2=[2], v_3=[3], v_4=[4]$.
This complex $K$ is of dimension $d=2$.
The group $C_p$ is a group of something called $p$-chains. Recall that a group is a set with a binary operation (in our case, addition) that is (i) associative, (ii) has an identity element, and (iii) has inverses. And when we refer to any group, instead of listing all the elements of the group all the time, it’s much more economical to talk about groups with respect to its generators. For the generators of $C_p$, we have to go back to $K$.
The $p$ in $C_p$ refers to the dimension of cells in $K$. A 1-chain of $K$, for example, is some strange abstract object that is generated by all the 1-cells of $K$, that is, we “add” up a bunch of 1-cells. So $e_1 + 2 e_5$ is an example of a 1-chain. It has no obvious geometric meaning (though, apparently, some people would disagree). If it helps, you can think of $C_p$ as a vectorspace whose basis is the set of $p$-cells of $K$ and the scalars are in $\mathbb{Z}$.
Figure 2: Relabeled and oriented.
Notice that the labeling of the vertices from Figure 1 gives us a nice built-in orientation, i.e., ordering, for each cell, see Figure 2. For example, edge $e_1 = [1 \, 2]$ so the orientation we give this edge is from $v_1$ to $v_2$ (because $1<2$). This orientation will help us define the additive inverse of a 1-cell. So $-e_1$ is what you would expect it to be; it’s just $e_1$ oriented in the opposite direction, from $v_2$ to $v_1$.
Now the definition states that $C_p$ is not just any old group. It is a free Abelian group. This is not as bad as it sounds. It just means, again, that we can just go back to thinking of $C_p$ like it’s a vectorspace.
So $C_p$ is free, which just means that every $p$-chain in $C_p$ can be uniquely written as $\sum_i n_i \sigma_i^p$, where $n_i \in \mathbb{Z}$ and $\sigma_p$ are $p$-cells. This idea should be deeply ingrained into your understanding of basis vectors in a vectorspace.
And $C_p$ is also Abelian. So our addition is commutative $\sigma + \tau = \tau + \sigma$ and that also let’s us keep thinking about this vectorspace idea.
So now that we know what the $C_p$ are, let’s talk about the homomorphisms $\partial_p$ between them. These homomorphisms have a special name; they are called boundary maps. This is where the geometry and combinatorics fit together very nicely. Let’s go back to our Figure 2.
The boundary of some $p$-cell $\sigma^p=[v_0 \, v_1 \, \dots \, v_p]$ is a $(p-1)$-chain with the alternating sum $$\partial_p(\sigma) = \sum_{i=0}^{p} (-1)^i [v_0 \, v_1 \, \cdots \, \hat{v_i} \, \cdots \, v_p ]$$ where $\hat{v_i}$ means you leave that vertex out.
For example, $\partial_1(e_1) = v_2 – v_1$ or $\partial_2(f_1) = \partial_2([2 \, 3 \, 4]) = [3 \, 4] – [2 \, 4] + [2 \, 3] = e_3 + e_5 – e_4$. This corresponds nicely with the figure. Just follow along the blue arrows on the boundary of $f_1$ from $v_2$ in a counter clockwise direction.
The boundary function works similarly for all dimensions $p$. For the higher dimensions, just keep in mind what I said earlier about orientation being determined by the labels. The orientation for an edge is easy to visualize, but not so much for, say, a 6-simplex. Everything works out nicely combinatorially with the above definition.
And because $C_p$ is a free abelian group, we see that the boundary map $\partial_p$ is a homomorphism. Notice also that $\partial_p \circ \partial_{p+1} = 0$. Whenever this happens (to any sequence of Abelian groups with homomorphisms between them with this property), we call such a sequence a chain complex.
Geometry of homology
Let’s introduce a few more important terms.
The set $B_p = \text{im}(\partial_{p+1})$ is the set of boundaries and the set $Z_p = \text{ker}(\partial_p)$ is the set of cycles (which, in German, is “Zyklus”).
So a cycle is any $p$-chain that sums up to zero. This is a very combinatorial/algebraic definition for a word that sounds very geometric. Intuitively, when you hear the word “cycle”, you might think of some path that closes, maybe like a loop. It’s very important, however, to recognize that “cycle” and “loop” (from homotopy theory) are very very different objects.
Let me go off on a short tangent here. Have you noticed that the word “curve” is different depending on who you talk to? For a physicist, a curve is a trajectory–a function $\gamma: [0,1] \to X$ for some space $X$. For a geometer, however, a curve is a subset of a space. Merely the image $\text{im}(\gamma)$. So it doesn’t matter whether a mosquito flies around in a circle 7 times or just once; it still traces just a single circle.
Analogously, a cycle doesn’t care about how you “go around the cycle” as long as the algebraic sum of the corresponding $(p-1)$-chains in the cycle adds up to zero.
And remember: since we have an Abelian group, the order of the addition (or “direction” of the cycle) doesn’t matter at all. For a loop, however, it matters whether you go around the loop clockwise or counterclockwise.
Let’s look again at the composition $\partial_p \circ \partial_{p+1} = 0$. It says, geometrically, that the boundary of $(p+1)$-chains are cycles. So the set of boundaries $B_p$ is contained in the set of cycles $Z_p$, i.e., $B_p \subseteq Z_p$.
Not only that, because $\partial_{p+1}$ is a homomorphism, $B_p$ is even a subgroup of $Z_p$. Geometrically speaking, the quotient group $H_p = Z_p / B_p$ means we partition the set of cycles $Z_p$ to those that bound and those that don’t. This means we can isolate cycles that do not bound cells. That is, we can find holes!
Figure 2: Relabeled and oriented.
Let’s go back to our example and think about $H_1 (K)$. The “simplest” 1-chains that make a loop are $e_1 + e_4 – e_2 = \ell_1$ and $e_3 + e_5 – e_4=\ell_2$. All other loops are some linear combination of $\ell_1, \ell_2$. For example $e_1 + e_3 + e_5 – e_2 + (e_4 – e_4) = \ell_1 + \ell_2$. So $Z_1$ is generated by $\ell_1, \ell_2$, i.e., $Z_1 = \{c\, \ell_1 + d\, \ell_2 \mid c,d \in \mathbb{Z} \} \cong \mathbb{Z}^2$. But we also know that $\ell_2 = \partial_{2} (f_1)$ and since $f_1$ is the only 2-cell in $K$, we have $C_2 = \{ c \,f_1 \mid c \in \mathbb{Z} \}$ and therefore $B_1 = \text{im}(\partial_{2}) = \{ c \, \ell_2 \mid c \in \mathbb{Z}\} \cong \mathbb{Z}$.
So $H_1 = Z_1/B_1 \cong \mathbb{Z}^2 / \mathbb{Z} \cong \mathbb{Z}$.
Using homology
Now that the homology group has been defined, we should know what it means. There is an important theorem in group theory that we should recall at this point. It’s so important that it is a fundamental theorem.
Theorem (Fundamental Theorem of Finitely Generated Abelian Groups) Every finitely generated Abelian group $G$ is isomorphic to a direct product \begin{align*}G \cong H \times T, \end{align*} where $H = \mathbb{Z} \times \cdots \times \mathbb{Z} = \mathbb{Z}^{\beta}$ is a free Abelian subgroup of $G$ having finite rank $\beta$ and $T = \mathbb{Z}_{t_1} \times \mathbb{Z}_{t_2} \times \cdots \times \mathbb{Z}_{t_k}$ consists of finite cyclic groups of rank $t_1, \dots, t_k$.
The $T$ is called the torsion subgroup of $G$; the $\beta$ is unique and called the Betti number of $G$; and the $t_1, \dots, t_k$ are also unique and called the torsion coefficients of $G$.
This fundamental theorem says that the homology group $H_p$ (which is a quotient group of a finitely generated Abelian group over a finitely generated Abelian group and therefore itself a finitely generated Abelian group) will always be isomorphic to something that looks like \begin{align*}H_p \cong \mathbb{Z}_{t_1} \times \cdots \times \mathbb{Z}_{t_k} \times \mathbb{Z}^{\beta}\end{align*} a finite direct sum of (finite and infinite) cyclic groups. So now all topological spaces can be nicely categorized by their homology groups according to their Betti numbers and torsion coefficients.
The homology groups $H_p$ are of dimension $p$ and each of them have an associated Betti number $\beta_p$. Since we figured out for our example that $H_1 (K) \cong \mathbb{Z} = \mathbb{Z}^1$, our Betti number $\beta_1 = 1$.
These Betti numbers have a wonderful geometric meaning. This number $\beta_p$ counts the number of $p$-dimensional holes in $K$. Ah, yes. We finally get to something meaningful and even useful!
Betti numbers can count, as in our example, the number of holes.
Since $\beta_1(K)=1$, this means $K$ has one 1-dimensional hole. And there is indeed a hole in $K$ (because there is no face $[1 \, 2 \, 4]$).
But what is a “hole”?
Honestly, I don’t know how to draw a good picture of a general $p$-dimensional hole (though examples of specific cases are easy). Thinking of holes like in homotopy theory–as the empty spaces where $p$-spheres $S^p$ cannot be shrunk down to a point–is a very nice and intuitive notion. But there are some spaces that, like the Poincare sphere for example, have $H_1 = 0$ and $\pi_1 \neq 0$. So it’s not enough to think about holes as the holes we see when working with fundamental groups.
We saw from the definition that homology groups are equivalence classes of cycles, of those that bound and those that don’t. So we collect all the “simplest” cycles and check whether they are the boundary of any faces. Any cycle that does not have a corresponding face which it bounds must bound a hole.
It turns out that counting holes has all kinds of industry applications. It can be used to analyze the structure of solid materials or proteins. It can be used in image processing or pattern recognition. It can even be used in robotics and sensor networks.
So homology algorithms have been developed to help these industry people to count holes. And now we know exactly how to write such an algorithm, right?
I realize that anyone reading this post doesn’t know what adipra is. How can you? I made it up.
The sphere I constructed most recently was an idea of Karim Adiprasito. While building it, I needed to name it so that I can refer to it in my code. So I temporarily named it adipra and that’s what I’m going to call it here.
Actually, in this post, I don’t want to talk about what adipra is. Not yet. Let’s talk just about what makes adipra special. For anyone who’s interested, all the specifics can be found here.
We need a little language to get started.
Def A combinatorial d-manifold is a triangulated d-manifold whose vertex links are PL spheres.
Let’s assume we know what a triangulated d-manifold means without hashing out the details here. If you need to, you can think of it as a simplicial complex.
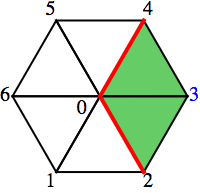
The star of a vertex v in a triangulated d-manifold T is the collection of facets of T that contain v. The link of a vertex v is like the star of v, but take out all the v‘s. For example, let’s take a simple hexagon with a vertex in the center.
That’s simple enough to understand even in higher dimensions. Just remember we’re always doing things combinatorially.
Next is the PL sphere. I said earlier that we can assume we know what a triangulated d-manifold is. What we’re actually talking about is a triangulated PL d-manifold. A PL-sphere is a PL manifold that is bistellarly equivalent to the boundary of a d-simplex. I’ll write in more detail what bistellarly equivalent means in a later post. For now, just think of it as the discrete version of being homeomorphic.
Putting all that together, we understand a combinatorial d-manifold to be a triangulated manifold, that is, some simplicial complex-like thing where we require that each of its verticies is sort of covered by a ball. Naturally, the next question to ask is: are there triangulated manifolds that are not combinatorial?
For d=2,3, all triangulations (of the d-sphere) are combinatorial. For d=2, the vertex links should be homeomorphic to $S^1$ or bistellarly equivalent to the triangle (boundary of a 2-simplex). Similarly, for d=3, vertex links are $S^2$. For d=4, all triangulated 4-manifolds are also combinatorial. This result is due to Perelman. The vertex links are 3-spheres, which, as you know, is what Perelman worked on. [Remember that PL=DIFF in dim 4.] But it falls apart for d$\ge 5$ as there are non-PL triangulations of the d-sphere.
Ok, so here’s a spoiler about adipra: it’s a non-PL triangulation of the 5-sphere. But that’s not all.
There’s a nice theorem by Robin Forman, the father of discrete Morse theory.
Theorem (Forman) Every combinatorial d-manifold that admits a discrete Morse function with exactly two critical cells is a combinatorial d-sphere.
Actually, this is not really Forman’s theorem. This is a theorem by Whitehead which Forman reformulated using his language of discrete Morse theory. This is the original theorem.
Theorem (Whitehead) Any collapsible combinatorial d-manifold is a combinatorial d-ball.
What Forman did is take a sphere, take out one cell, call that guy a critical cell, then collapse the rest of it down (using Whitehead’s theorem) to get the other critical cell. Thus you have two critical cells.
So the question you ask next is: can you have non-combinatorial spheres with 2 critical cells?
Yes, actually, you can! Karim showed that you can have a non-PL/non-combinatorial triangulation of the 5-sphere that has a discrete Morse function with exactly 2 critical cells! And then I built an explicit example (with Karim’s instructions) and called it adipra.
My first conference talk since starting Phase II was at KolKom 2012, the colloquium on combinatorics in Berlin. But I don’t know anything about combinatorics or optimization. What am I doing at a combinatorics conference!?
Actually, I don’t know much about anything. But it’s not hard to make me sound like I know about some things. The title of my talk was “constructing complicated spheres as test examples for homology algorithms”. Yes, algorithms! That’s the key! It was Frank’s idea to add the word “algorithms” to my title so that I can at least pretend to belong to this conference. It made for a very long title, but at least my abstract was accepted.
You can look at my slides, but I’ll give a short overview here.
We begin with a definition of homology and motivate some applications for homology algorithms. Betti numbers, in particular, are interesting for industrial applications. To compute the Betti numbers of some given simplicial complex, we will be dealing with matrices. We want to find the Smith Normal Form of these matrices. But the bigger the complex, the bigger the matrix, and the longer it takes to find the Smith normal form. So we throw the complex into a preprocess to reduce the size of the input. This preprocess uses discrete Morse theory.
Morse theory is used to distinguish topological spaces in differential topology. Forman came up with a nice discrete counterpart that conveniently preserves many of the main results from smooth Morse theory including the Morse inequalities. The Morse inequality $\beta_i \le c_i \; \forall i$ means that the Betti number $\beta_i$ is bounded above by $c_i$, the number of critical points of dimension $i$. Since our original goal was to compute Betti numbers, this result will definitely come in handy.
The critical points $c_i$ are the critical points of some discrete Morse function. These discrete Morse functions can be interpreted as a sort of collapse. By collapsing big complexes, we can reduce big complexes (that have big matrices for which we need to find the Smith normal form) to smaller complexes.
Ideally, we want to find the discrete Morse function with the lowest $c_i$’s. But computing the optimal discrete Morse vector, a vector $c = (c_0,c_1,c_2, \dots)$, is $\mathcal{NP}$-hard! So Lutz and Benedetti have come up with the idea of using random discrete Morse theory. Surprisingly, their algorithm is able to find the optimal discrete Morse vector most (but not all) of the time. To get a better idea of when they’re better able to find the optimum, they came up with a complicatedness factor which measures how hard it is to find that optimum.
That’s where I come in. I constructed some complicated simplicial complexes. They are being used to test some homology algorithms that are currently under development.
The first of my complicated complexes is the Akbulut-Kirby sphere, one of a family of Cappell-Shaneson spheres. These spheres have an interesting history. The AK-sphere, in particular, was one thought to be an exotic sphere. Exotic spheres are spheres that are homeomorphic, but not diffeomorphic to a standard sphere. In dimension $4$, this would mean it could be a counterexample to the smooth Poincar\’e conjecture, or SPC4 for short. Unfortunately, some years after the AK-sphere was proposed, it was shown to be standard after all. You can learn more about it here.
So I built an AK-sphere. Actually, I wrote code that can build any of the whole family of the CS-spheres. Before talking about what we did, let’s start with how these spheres are built. To understand the construction, you have to first accept two simple ideas:
The boundary of a solid ball is a sphere.
That’s not too hard to accept, which is why I said it first even though it’s the last step.
Given a donut, if you fill the “hole” (to make it whole, HA!), it will become a solid ball.
That’s also not too difficult to see. You can imagine the filling to be something like a solid cylinder that you “glue” onto the inside part of the donut.
Now for some language. This donut is actually a ball with a handle, which is known as a 1-handle. The filling for the hole is called a 2-handle. And we can specify how the 2-handle is glued in using an attaching map.
So to build the AK-sphere here’s what we do:
Take a 5-ball.
Attach two 1-handles. Let’s call one of them $x$ and the other $y$ so we can tell them apart.
Glue in two 2-handles to close the “holes” but use attaching maps that have the following presentation: \begin{align*} xyx&= yxy & x^r = y^{r-1}\end{align*}This means that the attaching map goes (on the boundary of the 5-ball) along $x$ first, then $y$, then $x$, then $y$ in the reverse direction, then $x$ in reverse, and finally $y$ in reverse. Similarly with $x^r = y^{r-1}$. [Note: For the AK-sphere, $r = 5$. By varying $r$ you get the family of CS-spheres.]
Take its boundary.
Since the 2-handles have closed the holes created by the 1-handles, what we have left after step 3 is again a 5-ball, though a bit twisted. So its boundary in step 4 should be a sphere.
To construct these spheres, we decided to go in a different order. It would be hard to imagine the attaching maps in dimension 5. So we went down a smidge to dimension 3. And instead of drawing the paths of the attaching maps on/in a ball, we built the ball around the paths.
As you might imagine, these paths come out a bit knotted. But by bringing them up in dimension, we can “untangle” it because there’s more space in higher dimensions. The way that we go up in dimension is by “crossing by $I$” where $I$ is the usual unit interval. Crossing by $I$ has the convenient side effect that everything you “crossed” ends up on the boundary of the resulting complex.
So we start with these two paths (some triangulated torii). We fill in the space between them with cleverly placed tetrahedra so that it ends up being a ball with two 1-handles. We now have a genus 2 simplicial complex, where two sets of tetrahedra are labelled as the path representing $xyx = yxy$ and the other $x^r = x^{r-1}$. Cross $I$, cross $I$ so that we are in dimension 5 with the two paths on the boundary of this ball with two 1-handles. Glue in the (5-dimensional) 2-handles (whatever that means). Take the boundary. Done!
The experiments we’ve run on them so far have shown some promise. The complexes are not too large (with f-vector$=(496,7990,27020,32540,13016)$) so the experiments don’t take too long to run. They’ve already been used by Konstantin Mischaikow and Vidit Nanda to improve their on-going Perseus algorithm. [edit: In the original post, I mistakenly referenced CHomP, which has been static for some time.]
The other complex I constructed is Mazur’s 4- manifold. We do a similar thing, but this time there’s only one path to deal with (that is, only one 1-handle to close up with one 2-handle). The results from this one has some nice topological properties. I’ll get to that in a later post once we’re ready to publish.